![]()
ヒストグラム, 工程能力指数, Cp, Cpk
ヒストグラム(度数分布図)は、バラツキの分布の形を表し、そこから分布の異常を診断します。
工程能力指数Cpによって、規格巾Tに対するバラツキの大きさの合否を判定します。
工程能力指数Cpkによって、規格巾Tに対する平均値とバラツキの大きさの合否を判定します。
ヒストグラムの作図、および、平均値、標準偏差はExcelで計算します。CpとCpkは、標準偏差が分かれば容易に計算できます。
1.ヒストグラムとは
単なる偶然のバラツキかどうか、まずは分布の形が問題だ。
ヒストグラムは、一群の数値データを「値の大きさによって区分」し、各区分に属するデータ個数の度数分布表を図化した一種の棒グラフであり、データのばらつき具合(分布形状)を可視化して診断する重要な手法である。
かつて標準偏差の値をヒストグラムから計算したが、現今では標準偏差は Excel で簡単に求められ、その役目は終わった。
現在、ヒストグラムは、「分布の形」だけを診断の対象にしている(広がりや平均値は、 → 工程能力指数 Cpk で診断する)。
工程能力指数:Cpkに異常がある場合の分布確認
「離れ小島」のような分布の異常の確認
エクセルによる作成例
Excelを使ってヒストグラムを作成する方法は、3つ程ある。
- 区分ごとの頻度データから棒グラフを作成する。
- アドインを利用する。
- 関数を利用する。
以上のうち最も簡単な方法は最初に挙げたやり方であって、下のように作成する。
- データ数 n=50個~200個を揃える。
- 最小値 xminと最大値 xmaxを求める。
- 範囲 R = xmaxーxminを求める。
- 柱(区分)の数 N ≒ n の平方根(n=100なら、N≒10)
- 柱(区分)の巾 h=R/N
- 区分の左右の境界値を求める。
xmin-h/2 ≦ xmin+h/2
(xの最小値ー幅の半分≦xの最小値+幅の半分)
xmin+h/2 ≦ xmin+3h/2
(xの最小値+幅の半分≦xの最小値+幅の1.5倍)
xmin+3h/2 ≦ xmin+5h2
・・・・・・・ - 各区分の中央値を求める。
- 各区分に属するデータ数(頻度)を求める。
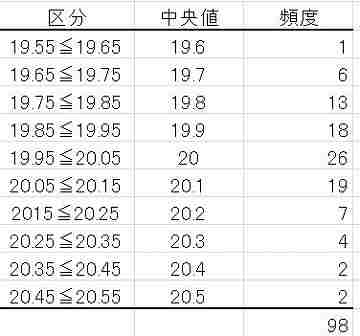
以下の事例で、次のようになったものとする。
- データ数 n=98
- 柱(区分)の数(98の平方根)=9.91≒10個
- 最小値=19.6 最大値=20.5
- 範囲 R=20.5-19.6=0.9
- 区分の巾 h=0.9/10≒0.1
- 区分の境界
19.55≦19.65(19.55を超え19.65まで)
19.65≦19.75
・・・・ - 頻度は、その区分に含まれるデータの個数
Excel を使って、中央値と頻度から、次のヒストグラムを得る。
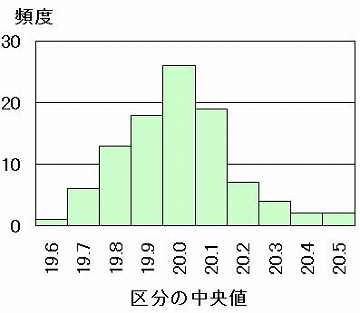

データ数が少なく柱の数が多いと山の形が「歯欠け婆さん」のようにキザキザになる。
データ数が少なく柱の数を少なくすると大ざっぱな山形ができ上るだけで、ふた山や離れ小島のような重要な情報は得られない。
2.山の形の診断
(a)理想の分布形状
富士山のように綺麗な山形状が理想である。理想形は、分布を生む条件が厳格に同一で、しかも無限数のデータを得た場合の分布である。
従って、実際のデータで作ると理想形はほとんど見られない。
(b)すそ引き型
下限値が0で負の値にならない特性で、0付近に分布する場合である。
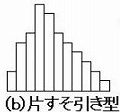
例えば、板のそり、不純物の含有%など。そういう条件がないのにこれに似ると分布異常である。
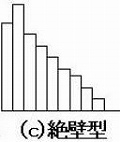
(c)絶壁型
選別した場合に起きる分布である。合格ロットであっても、出荷には支障ないが、生産工程は改善を要する。
(d)高原型
平均値が僅かに異なる数個のロットが混ざった場合の分布である。この場合は3ロッと程が混ざっているように見える。
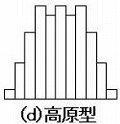
ロットごとに層別した上でヒストグラムを作って、平均値が変化する原因を追究する必要がある。
→ 二山の例
(e)ふた山型
高原型の特殊な場合である。平均値の異なる2個の分布が混入した場合の分布である。この図は一見して二山と分かるが、平均値が接近すると高原型に見え、一方の山が低いと単なる変形山に見るので注意を要する。
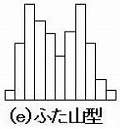
層別ヒストグラムで、平均値や標準偏差の異なる分布が混ざっていると分かったら、原因を追究する必要がある。
(f)離れ小島型
異なった分布のデータが僅かに混入した場合の分布。理屈は簡単だが、見つけにくい点で一番の難物であり、一番解消の必要性が高い。

離れ小島を避けるためには、多くの機会に、大量のデータでヒストグラム作成して診断する必要がある。
離れ小島の原因として、次のようなものがある。
- 段取り時の試作品を「チョイ置き」で混入
- 型交換時に前型品を「チョイ置き」で混入
- 不良品を、故意または過失で混入
- 余った製品を在庫し、次回ロットに混入
- 作業指導で作ったワークが混入
- 落下品を拾って混入
標準偏差の計算がパソコンに奪われた現在、ヒストグラムの意義はもっぱら「ふた山」や「離れ小島」の発見にある。
3.工程能力指数 Cp、Cpk
Cp によって、バラツキの大きさが規格幅に対して妥当かどうか、判定します。
Cpk によって、バラツキの大きさと平均値が規格の上限値と下限値に対して妥当かどうか、判定します。
なお、ヒストグラムから、平均値、標準偏差、Cp、Cpk等を計算するオンラインソフトを利用することができる。
→ 度数分布の計算
ヒストグラムを介しないで、直接データを投入して、平均値、標準偏差、Cp、Cpk等を計算するオンラインソフトを利用することもできる。
→ 度数分布の計算
Cp、Cpk の意味をよく理解するには、この後に説明するように、自分でExcelを使って計算するのが最善である。
(1)Cp(シーピー)
工程能力指数Cpとは、規格幅に対する「データのバラツキの余裕」を示す指数である。
工程を診断するには、まず、バラツキの巾が広くないか、診断せよ。
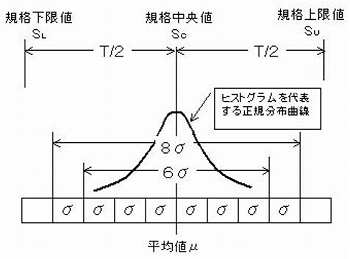
3-2 図の山の形をした図形は「ガウスの正規分布曲線」と呼ばれるもので、理想型ヒストグラムを代表した図形である。
記号の意味
規格下限値:SL
規格中央値:SC
規格上限値:SU
標準偏差:σ
Cpは、分布の平均値μと規格中央値SCが一致するかどうかを問わずに、標準偏差(ばらつきの大きさ)のみを問題とする。
1.標準偏差と平均値を表す文字は、2種類ある。
2.数学上の理論値の場合は:σ、μで表す。
実際のデータから求めた場合は![]() で表す。
で表す。
(![]() を、エックスバーと呼ぶ)。
を、エックスバーと呼ぶ)。
これら平均値と標準偏差の Excel による計算方法は、このページの最後 に示してある。
第3-2図に戻る。
正規分布を前提にすると、データの存在範囲は99.7%が「μ±3σ」の中に入り、ここから外側に外れるデータは、1,000個中の3個ほどしかない。
従って、「μ±3σ」と規格の上限・下限が一致すれば少し安心できる。この状態を次のように表す。
工程能力指数: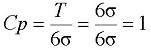
しかし、この状態は余裕がなく、少しの変化ですぐに規格外のデータが発生しかねない。そこで両側にもうσだけ外側に規格の上限・下限を置けば安心である。この安心できる状態を次のように表す。
工程能力指数: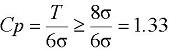
つまり、Cpの値が1.33以上なら、バラツキ幅に関する限り安心できる。
実施例 → トヨタの事例
(2)Cpk(シーピーケイ)
Cpk とは、現実のデータの平均値が規格の中央からずれている場合の、規格幅に対するバラツキの余裕を示す指数である。
平均値:μが、規格中央値:SCからδだけずれている場合を第3-3図に示す。
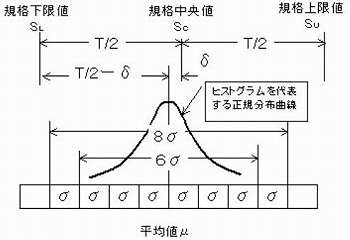
この場合、余裕が減った側(危険な側)、この図では左側の片側規格巾が、次のように減ったことになる。
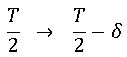
故に、左半分について計算する。
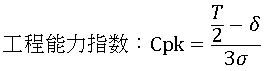
これが、1.33 以上でなければ安心できないことになる。
(3) データ数nによる修正
データの数は、何個あればいいの?
CpにしろCpkにしろ、もう1つ問題がある。何個のデータが必要か?
今までの話はガウスの正規分布という数学の理論であって、データ数が無限にあるとの前提に立っている。従って、現実の有限のデータから計算する工程能力指数は 1.33 では足りないのだ。
そこで、専門家の末武先生の指導を受けて、第3-4図グラフを得た。
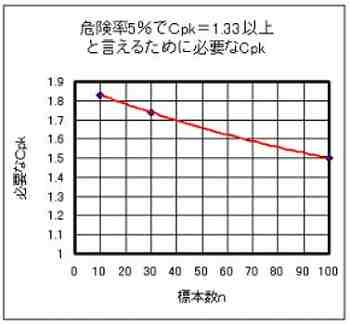
n=100個ほどのデータなら、1.5以上
n=20個ほどのデータなら、1.8以上
~という具合に大きなCpとCpkが必要になる。
(4)平均値の計算
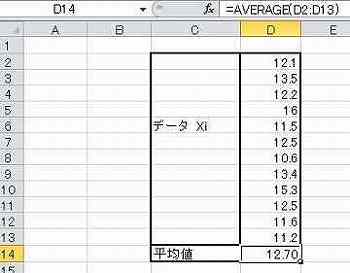
Excel で平均値を計算する。
母集団のデータ数は無限であるが、この中から有限のサンプルデータを得たものとして、範囲 (D2~D13) に列挙してある。
使用する関数=AVERAGE
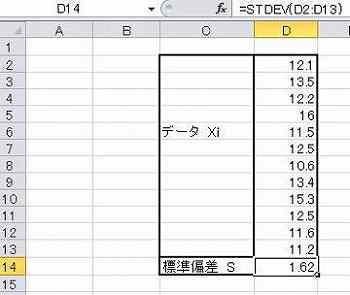
(5)標準偏差の計算
Excel で平均値を計算する。上と同じデータである。
使用する関数=STDEV
All rights reserved.
© 客観説TQM研究所 鵜沼 崇郎