![]()
6.層別,事例,直交配列表
層別は、QC活動にとって最強の手法である。慢性不良は、この手法で最も迅速に対応することができる。
この章で紹介することは、次の通りである。
層別とは、データを「層(=種類)」で分けることによって生じる差(層間差)を見て有益な情報を引き出す手法をいう。
層別には、特性の層別、要因の層別、結果の層別という3種類がある。
多数の要因を層別する手法として、QCサークルが使用できる簡単な直交配列表の例題を解説する。
目次
1.層別とは1-1. 特性の層別
1-2. 要因の層別
例1:2台の機械
例2:原料
例3:Histogram
1-3. 結果の層別
2.直交配列表
2-1. 有益性
2-2. 演習と解説
・例題
・水準 ・割付け
・実験番号
・実験の実施
・結果 / 不良個数
・第1列の計算
・第2列の計算
・全ての列の計算
・検証
・結論
1.層別とは
層別(Stratification)とは、何かの種類ごとにデータを分けて、種類による差を観察して、その差の意味を検討することをいう。
データは、一般に、いろいろな情報が混入して成り立っているため、そのままでは有益な情報を取り出すことができない。
しかし、層別して層間差を見ることにより、有益な情報を引き出すことができる。
1-1. 特性の層別
パレート図を参照して下さい。
参照 → パレート図
1-2.要因の層別
生産工程に同じ働きをする1号機と2号機があるなら、不良データを号機ごとに分けてみよう。
例1:2台の機械
生産工程に同じ働きをする1号機と2号機があり、両機とも正常なら発生する不良率も等しいはずである。
それぞれ100個加工してデータをとってみたら、1号機で30個の不良が発生し2号機で6個であった。このようなことを数回やってみて、毎回1号機に不良が多いなら、1号機に原因が潜んでいる。
この場合、機械の号機が「要因」で、1号機・2号機という「水準」が「層」である。そして、1号機と2号機の差が「層間差」である。
例2:原料メーカー
上の事例1の1号機で生じた不良品30個を、原料メーカー別に分けた。するとA社の原料から作ったものは約半分が不良で、B社の原料ではゼロであった。つまり不良は、A社の原料を使って1号機で加工したものに多いことが分かった。
この場合、原料メーカーが要因でA社・B社という水準が層である。
〔注〕層別する要因の数が多いときは、→ 直交配列表 を使うのが便利である。
例3:ヒストグラム
下図左側の不規則なヒストグラムが得られた。
左右が対象でないことに着目して、原料メーカーA社とB社に分けてみると、右側の図の実線と鎖線のように二山型だと判明した。
この場合、原料メーカーが「要因」、ヒストグラムのデータを分けることが「層別」であり、2つのヒストグラムの違いが「相関差」である。
一見、二山に見えず 層別で二山が明確に
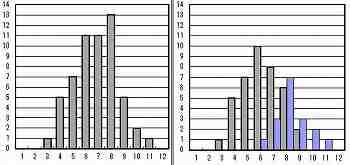
〔非常に参考になる事例〕 → 棒グラフで要因の層別
1-3.結果の層別
要因Xと要因Yの対データが得られ、XもYも適切に管理しているはずなのに不良が発生する場合。
温度Xと成分量Yの散布図において、不良品と良品に分けると〔第6b図〕のようになった。
ここから、不良品を生まない条件を選定することができる。
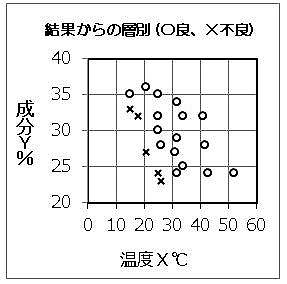
上図から、成分Yが薄い時は温度Xを高めにしなければならないことが分かる。このようなXとYの関係を「交互作用」という。
2.直交配列表
QCサークルが使える「やさしい直交配列表の使い方」を説明しよう。
2-1. 直交配列表の有益性
多数の要因を同時に層別して、最適条件を求め、あるいは不良を再現する。
いま、ある特性Xの慢性不良にてこずっているとする。
「疑わしい要因」は次の特性要因図の〇で囲った5個であるが、それぞれ決められた範囲に収まるよう管理している。それでも不良が発生する。
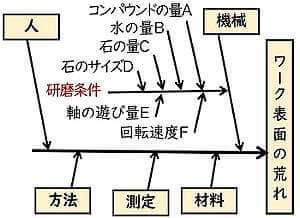
- 他にも原因があって管理していないから不良が出るのか、
- 分かっている5個の要因の水準の組合せで起きるのか、
~さっぱり分からない。
そこで、疑わしい要因5個と「もしかしたら要因かも知れないもの」を1個加えた計6個の要因について、直交配列表による層別実験をしてみよう。
この実験により、各要因の影響力の強さ、および、不良が発生する再現条件を割り出すことができる。
ところが直交配列表の使い方を解説する書物は「実験計画法」と題した著書だけで、これを学ぶ人は限られ、一般には存在すら知られていない。
大学の理科系学部でも、履修科目として選択する学生は少なく、まして企業の作業者・下級・中級・上級職員などで直交配列表を利用する人は極めて少ない。
その原因は、正式な実験計画法では、直交配列表を分散分析・f検定・平均値の推定などの統計処理を前提に使うものとしていることにある。これだと、一般の人は数式を見ただけで頭が痛くなって手が出せない。
筆者は、全く統計処理をせずに直交配列表を使うことを小集団活動に推奨している。それで何の問題もなく、コンピュータ・ソフトを使う必要もなく、きわめて便利に使える。
知っている人には無用な説明だが、初心者のために例題を示そう。一度覚えれば目をつむっても使えるから、最初だけ丁寧に読んで頂きたい。
2-2. 演習と解説
筆者が実際に経験した具体的な事例について解説する。
例題
薄い円盤状の金属製品の「仕上げ処理工程」で、表面が異常にザラザラした「面荒れ」という不良が出ることがある。
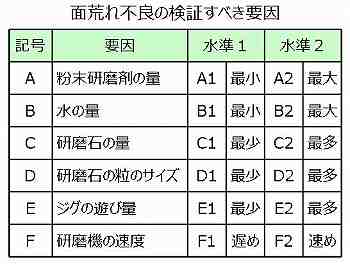
要因としてA、B、C、Dがあり、これらは一定の範囲に収まるように管理しているはずだが、あるいは管理が行き届かずに範囲を超えてしまう要因があるかも知れない。
また、影響力があるにもかかわらず、管理の対象としていない要因E、Fがあるかも知れない。そこで、これら6個について直交配列表で検証する。
水準
要因Aの影響力を調べるには、Aを日常的に変わり得る範囲内で変化させてみて、それに対応して特性がどう変わるかを見る。すなわち、~
1. 「量的要因」の場合は、日常用務で実際に生じ得る最小値と最大値の2水準で実験する。
2. 「層別要因」の場合は、1号機と2号機、X社の材料とY社の材料~という具合に、2水準にする。
〔注〕要因に与える変化(段階)を「水準」といい、全ての要因を2水準に変化させる実験を「2水準系の実験」という。
各要因の水準を下図のように設定する。
下の第6d図は、最多7個の要因を扱える2水準8回実験型の直交配列表:L8(27) である。小規模な実験では、最も多く使われるタイプである。
この図を見て意味が分からなくても心配は不要であり、覚える必要もない。ただ、どの列にも1と2が4つあり、配置を規則的に変えてあることを確認して欲しい。
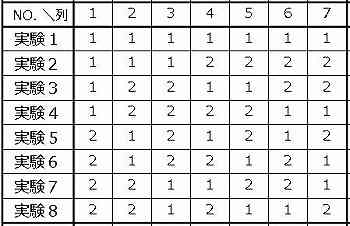
割付け
下の表の「要因欄」に要因の記号A、B、C・・・を記入する。要因の名称を記入してもよい。
記入する要因の数は、ここでは6個であるが、最多で7個の記入が可能である。
空白になった列は、e (error:誤差の意味)の文字を記入する。
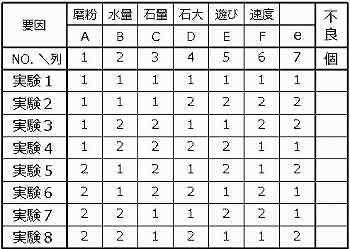
実験番号
左端列の縦の1~8は実験番号であり、8回の実験をする。
実験を行なう順序は、必ずランダムな順にすること。番号順や逆順に実行すると、考慮していない要因の影響を受けて実験誤差が増えるからである。
例えば、朝の気温が低いときにNO.1から順に実験を始め、気温が高くなった正午にNO.8で終了したとすると、A1とA2の差に「気温の影響」が混入し、実験の精度が悪くなる。
実験の実施
下図のように、実験番号2の実験は、A1・B1・C1・D2・E2・F2 の組合せで行う。その結果、1,000個中に80個の面荒れ不良が発生したら、不良記録欄に80と記載する。個ではなく%で記入してもよい。
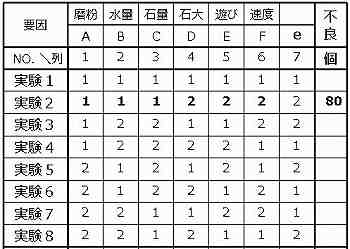
結果・不良個数
n=1,000個投入した実験を8回行って、各実験で+発生した面荒れ不良の個数を右端に記載する。
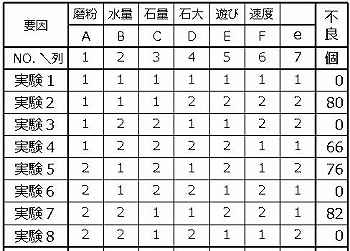
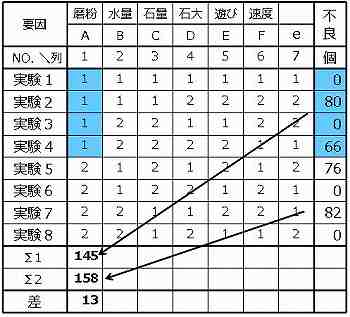
第1列の計算
要因AのA1を使った4個の結果の合計値(145)をΣ1の欄に記載し、A2のそれ(158)を∑2に記載し、差の絶対値(13)を差の欄に記載する。
第2列の計算
要因BのB1を使った4個の結果の合計値(156)をΣ1の欄に、B2のそれ(148)を∑2に記載し、差(8)を記載する。
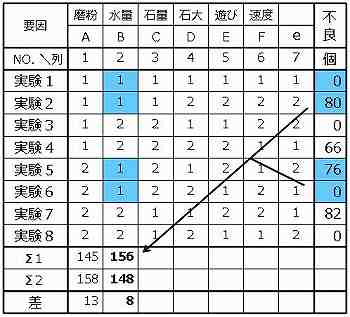
全ての列の計算
全列の計算の結果を下表に示す。割付けをしなかった第7列eについても同様に計算する。
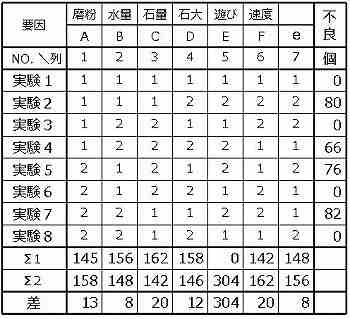
検証
表の一番下の「差」の値が各要因の影響力を示す。これを棒グラフに表してみよう。
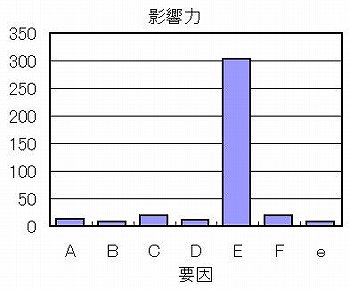
要因Eのみがダントツである。
第7列は何も割り付けておらず本来ゼロであるべきところ、実験誤差e(ノイズ)がこの程度であることを示す。
するとE以外の要因はこの実験誤差eと同等だから、面荒れ不良に関する限りは全く関与していないことが分かる。
結論
要因E(ジグの遊び量)が過大であったことが原因である。
最小値E1では発生せず、最大値E2で発生するので、その間のどこかに境界水準が存在する。今後、この境界水準を明らかにするための実験を行う。
それには、E1~E2の中央の値E3で実験して、その結果によって次の値E4を決めて実験するように継続する。
〔注〕
この実験では第7列に何も割り付けないで空欄(誤差eの列)にしたが、敢えてこのような扱いをせずに全列に要因を割り付けても支障ない。なぜなら、問題となる要因はせいぜい1~2個であって、他の要因は誤差eと同等になるからである。
All rights reserved.
© 客観説TQM研究所 鵜沼 崇郎